发布日期:
2023-07-18
更新日期:
2023-07-26
文章字数:
3.1k
阅读时长:
11 分
FEMU
预备知识
QEMU
- https://blog.csdn.net/fontthrone/article/details/104157859
AIO
- AIO ( Asynchronous I/O):异步非阻塞I/O模型。异步非阻塞与同步非阻塞的区别在哪里?异步非阻塞无需一个线程去轮询所有IO操作的状态改变,在相应的状态改变后,系统会通知对应的线程来处理。对应到烧开水中就是,为每个水壶上面装了一个开关,水烧开之后,水壶会自动通知水烧开了。
MMIO
- https://zhuanlan.zhihu.com/p/37715216
Open Channel SSD
- https://blog.xiocs.com/archives/4/
FEMU论文阅读:The CASE of FEMU: Cheap, Accurate, Scalable and Extensible Flash Emulator
简介
- FEMU,一个基于qemu的flash模拟器。
- 具有以下四个优势:免费开源,模拟SSD准确,可拓展,支持内部修改。
Motivation
- ①回顾近十年存储会议论文,统计如下数据:研究规模,使用平台,修改层级。
发现最多的类别是:针对单SSD,使用模拟器,修改底层SSD控制器逻辑。
- ②缺乏大规模SSD研究:少数大规模SSD研究也是大公司花费巨大进行的,严重损害多节点仿真研究。
- ③软件定义闪存的兴起:之前多在FPGA平台上完成的,价格不菲。
- ④拆分级架构的兴起:大多数现有的研究修改单层(应用程序/内核/SSD),但最近的一些工作显示了“拆分级”架构的好处,其中一些功能向上移动到操作系统内核,而另一些向下移动到SSD固件。
- ⑤现有模拟器的状态:三种流行的基于软件的模拟器:flash, LightNVM的QEMU和VSSIM。各有缺点。
- 所以是时候建立一个新的模拟器来跟上技术的发展趋势了。
设计与实现
- SSD研究的典型软硬件组合为{应用程序+主机操作系统+SSD设备}。对于FEMU,栈是{Application+Guest OS+FEMU}。
- ①可拓展性:
QEMU在线程增大过程中延迟太高,因为QEMU使用传统发发模拟IO,并且使用AIO开销较大。
解决方案:把中断变为轮询,并禁用Guest OS中的门铃写入,创建了一个专用线程来连续轮询设备队列状态。然后跳过AIO组件,在QEMU中创建自己的RAM支持的存储。
- ②准确性:
Ⅰ:延迟机制:
当一个IO到达时,FEMU将发出DMA读/写命令,然后用模拟完成时间(Tendio)标记该IO,并将该IO添加到“endio队列”中,根据IO完成时间排序。FEMU专用了一个“end-io线程”(取带原来QEMU的中断机制),一旦IO的模拟完成时间超过当前时间(Tendio>Tnow),它就会持续从队列头部接收IO,并向Guest OS发送一个end-io中断。(一旦超过模拟时间就继续处理剩下的IO)
Ⅱ:基础延迟模型:
用模型准确计算每个IO的end-io time (Tendio),计算每个channel和plane的下一个空闲时间Tfree,例如,如果页面写入到达当前空闲的通道#1和平面#2,那么我们将提前通道的下一个空闲时间(TfreeOfChannel1=Tnow+Ttransfer,其中Ttransfer是通道上可配置的页面传输时间)和平面的下一个空闲时间(TfreeOfPlane2+=Twrite,其中Twrite是NAND页面的可配置写入/编程时间)。因此,该写操作的io结束时间为Tendio=TfreeOfPlane2。如果在进行写操作时,对同一plane的页面读操作到达。在这里,我们将通过Tread来推进Tfreeofchannel2,其中Tread是一个可配置的NAND页读取时间,并通过transfer来推进TfreeOfChannel1。这个读的IO结束时间将是Tendio=TfreeOfChannel1(因为这是读操作而不是写)。
总之,这个基本队列模型表示一个单寄存器和统一页面延迟模型。每个plane只有一个页面寄存器,因此不能并行服务多个IO(即一个平面的Tfree表示该平面的IO序列化),NAND页面的读、写和传输时间(Tread、Twrite和ttransfer)都是单个值。且GC逻辑可以很容易地添加到这个基本模型中;GC本质上是一系列的读/写(和擦除,Terase),也将推进平面和通道的Tfree。
Ⅲ:高级延迟OC模型:
我们将展示如何扩展我们的模型并实现更准确的OpenChannel SSD(简称“OC”)延迟仿真。
但OC的NAND硬件有以下复杂之处。首先,OC使用双寄存器平面;每个平面都有两个寄存器(数据+缓存寄存器),因此一个平面上的NAND页读/写可以与通过通道到该平面的数据传输重叠(即,更多的并行性)。
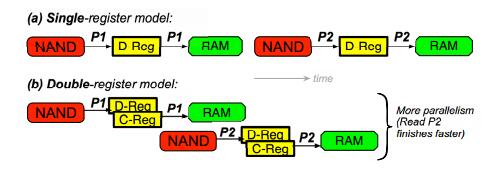 图1对比了单寄存器和双寄存器模型,在双寄存器模型中,第二个IO到页面P2的完成时间更快。(a)在单寄存器模型中,一个平面只有一个数据寄存器(DReg)。直到P1使用寄存器完成(即,传输到控制器的RAM完成),才能开始读取页面P2。(b)在双寄存器模型中,P1被读入数据寄存器后,它被快速复制到缓存寄存器(D-Reg到C-Reg)。由于数据寄存器是空闲的,可以开始读取P2(与P1向RAM的传输并行),因此完成得更快。其次,OC使用非统一的页面延迟模型;也就是说,映射到MLC单元的上位(“上”页)的页面比映射到下位(“下”页)的页面产生更高的延迟。
图1对比了单寄存器和双寄存器模型,在双寄存器模型中,第二个IO到页面P2的完成时间更快。(a)在单寄存器模型中,一个平面只有一个数据寄存器(DReg)。直到P1使用寄存器完成(即,传输到控制器的RAM完成),才能开始读取页面P2。(b)在双寄存器模型中,P1被读入数据寄存器后,它被快速复制到缓存寄存器(D-Reg到C-Reg)。由于数据寄存器是空闲的,可以开始读取P2(与P1向RAM的传输并行),因此完成得更快。其次,OC使用非统一的页面延迟模型;也就是说,映射到MLC单元的上位(“上”页)的页面比映射到下位(“下”页)的页面产生更高的延迟。
Ⅳ:测试:
通过结合这个详细的模型,FEMU可以作为OC的精确替代,我们用以下结果证明了这一点。
结果1: 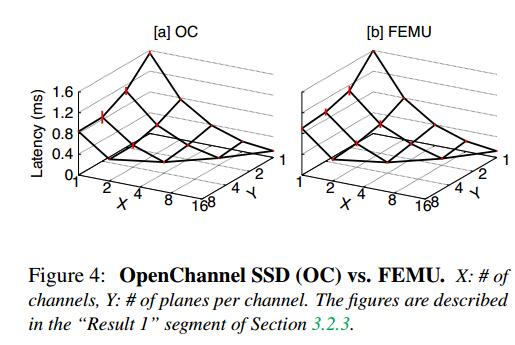 图2比较了OC和FEMU上的IO延迟。工作负载是16个IO线程执行随机读取,均匀分布在整个存储空间中。我们将存储空间映射为不同的配置。例如,x=1和y=1意味着OC和FEMU只配置了1个通道和1个平面/通道,因此,由于所有16个并发读取都在争夺同一平面和通道,因此平均延迟很高(z>1550µs)。x=16和y=1的结果意味着我们使用16个通道,一个平面/通道(总共16个平面)。在这种情况下,并发读取被所有平面和通道并行吸收,因此平均读取延迟更快(z<130µs)。
图2比较了OC和FEMU上的IO延迟。工作负载是16个IO线程执行随机读取,均匀分布在整个存储空间中。我们将存储空间映射为不同的配置。例如,x=1和y=1意味着OC和FEMU只配置了1个通道和1个平面/通道,因此,由于所有16个并发读取都在争夺同一平面和通道,因此平均延迟很高(z>1550µs)。x=16和y=1的结果意味着我们使用16个通道,一个平面/通道(总共16个平面)。在这种情况下,并发读取被所有平面和通道并行吸收,因此平均读取延迟更快(z<130µs)。
总的来说,图4a和图4b展示了一个非常相似的模式,显示了我们的队列延迟模拟的成功。
结果2:  y轴表示OC与FEMU上基准测试结果的延迟差(error) (error =(Latfemu−Latoc)/Latoc)。D-Reg和S-Reg分别代表高级模型和基本模型。图(a)和图(b)中两条粗体边条是相同的实验和配置(16个平面上16个线程的varmail)。
y轴表示OC与FEMU上基准测试结果的延迟差(error) (error =(Latfemu−Latoc)/Latoc)。D-Reg和S-Reg分别代表高级模型和基本模型。图(a)和图(b)中两条粗体边条是相同的实验和配置(16个平面上16个线程的varmail)。
图3a显示了运行几个具有六个文件工作台特性的宏基准测试的结果,这些宏基准测试在4个通道的16个平面上具有16个IO线程的并发读/写。该图仅显示了延迟差异(误差),它对比了我们的基本和高级延迟模型的准确性。使用基本模型,得到的延迟非常不准确(1257%),但是使用高级模型,误差下降到只有0.5-38%,在六个基准测试中精度提高了1.5-40倍。
进一步研究了残差,如图3b所示。这里我们使用varmail个性,但我们改变了#IO线程和#plane。例如16thread16plane配置(图5b中x= “ 16T16P “,与图5a实验中使用的配置相同),误差为38%。然而在不太复杂的配置中,误差会减小(例如,1T1P上的误差为0.7%)。因此更大的错误来自更复杂的配置(例如,更多的IO线程和更多的plane)。
结果3:
我们发现使用高级模型需要更多的CPU计算,并且这种计算开销会随着线程数的增加而积压。为了证明这一点,图1b比较了我们的原始实现和高级模型中简单的+50µs延迟仿真。在这里,这两种情况都只是添加+50µs,但是高级模型必须遍历许多if-else语句(以检查寄存器、平面和通道下一次空闲时间),因此计算开销很大。 - ③可用性和可拓展性:
从以下几个方面阐述FEMU可用性以及未来扩展:
• FTL和GC方案:
默认采用FTL动态映射和通道阻塞GC。我们的项目使用FEMU来比较不同的GC方案:控制器、通道和平面阻塞。在控制器阻塞GC中,GC操作“锁定”控制器,阻止任何前台IOs被服务(如OpenSSD)。在通道阻塞GC中,只有涉及GC页面移动的通道被阻塞(如SSDSim)。在最有效的平面阻塞GC中,页面移动仅在平面内流动,而不使用任何通道(即“回拷”)。样例结果如图4a所示。除了我们的工作之外,最近的工作还显示了SSD分区对性能隔离的好处,这些工作是在模拟器或硬件平台上完成的,还可以使用FEMU探索更多的分区方案。
 • 白盒vs黑盒模式:
• 白盒vs黑盒模式:
FEMU可以用作白盒设备,如OpenChannel SSD,设备公开物理页面地址,FTL由操作系统管理,如Linux LightNVM;也可以用作黑盒设备,如商用SSD, FTL驻留在FEMU中,只有逻辑地址暴露给操作系统。
• 对闪存阵列研究的多设备支持:
FEMU是可配置的,可以作为多个设备出现在Guest OS中。例如,如果FEMU暴露了4个ssd,那么在FEMU内部将有4个独立的NVMe实例和FTL结构(没有重叠的通道)在单个QEMU实例中进行管理。以前的模拟器(VSSIM和LightNVM的QEMU)不支持此功能。
• 可扩展的OS-SSD NVMe命令:
由于FEMU支持NVMe,可以添加新的OS-to-SSD命令(例如,用于主机感知的SSD管理或分层架构)。例如当前在LightNVM中,GC操作从OC读取有效页面到主机DRAM,然后将它们写回OC。
这会浪费主机ssd PCIe带宽;LightNVM前台吞吐量在GC下下降了50%。但可以从操作系统向FEMU/OC添加新的“pageMove fromAddr toAddr”NVMe命令,这样数据移动就不会跨越PCIe接口。如前所述,分层架构是趋势,我们的nvme驱动的FEMU可以扩展到支持更多的命令,如事务、重复数据删除和多流。
• 页面级延迟可变性:
如前所述,FEMU支持页面级延迟可变性。高质量的芯片和低质量的芯片混在一起,而坏的芯片会导致更高的错误率,需要更长的时间,在不同的电压下重复读取。FEMU也可以扩展以模拟这种延迟。
• 分布式SSD:
FEMU的多个实例可以很容易地部署在多台机器上(就像运行Linux管理程序kvm一样简单),这促进了更大规模的SSD研究。例如,我们还能够在运行FEMU的机器集群上评估Hadoop的单词计数工作负载的性能,但使用不同的GC方案,如图4b所示。由于HDFS使用大型IOs,最终会在许多通道/平面上分割,因此通道和平面阻塞之间的性能差距较小.我们希望FEMU可以激发更多的工作,修改SSD层来加速分布式计算框架(例如,分布式图形处理框架)。
• 页面级故障注入:
除了与性能相关的研究之外,闪存可靠性研究也可以利用FEMU(例如,通过注入页面级损坏和故障并观察高级软件堆栈如何反应)。
• 限制:
FEMU支持dram,因此不能模拟大容量ssd。此外,对于崩溃一致性研究,FEMU用户必须手动模拟“软”崩溃,因为硬重启将擦除DRAM中的数据。结论
随着现代SSD内部变得越来越复杂,应该研究它们对整个存储堆栈的影响。FEMU是一个合适的研究平台,希望廉价可扩展的FEMU可以加速未来SSD的研究。



