发布日期:
2023-07-17
更新日期:
2023-07-19
文章字数:
4.5k
阅读时长:
15 分
KVSSD
预备知识
LSM树
- 目前HBase,LevelDB,RocksDB这些NoSQL存储都是采用的LSM树。LSM树的核心特点是利用顺序写来提高写性能,但因为分层(此处分层是指的分为内存和文件两部分)的设计会稍微降低读性能,但是通过牺牲小部分读性能换来高性能写,使得LSM树成为非常流行的存储结构。
- https://zhuanlan.zhihu.com/p/181498475
- https://www.jianshu.com/p/e89cd503c9ae?utm_campaign=hugo
RocksDB介绍
- Rocksdb 是基于Google LevelDB研发的高性能kv持久化存储引擎,以库组件形式嵌入程序中,为大规模分布式应用在ssd上运行提供优化。RocksDB不提供高层级的操作,例如备份、负载均衡、快照等,而是选择提供工具支持将实现交给上层应用。正是这种高度可定制化能力,允许RocksDB对广泛的需求和工作负载场景进行定制。
- https://zhuanlan.zhihu.com/p/615110916
非关系型数据库
- https://zhuanlan.zhihu.com/p/112340622
RAID
- https://zhuanlan.zhihu.com/p/51170719
简介
- 键值存储存在问题:
SSD高带宽没法充分利用,IO中数据管理开销大(压缩操作),维护键值对一致性开销大,结点可伸缩性差(CPU需要产生巨大IO才能使得SSD带宽利用)
- 所以设计内部管理可变长度键值对的KV-SSD,通过将键值管理层卸载到SSD,可以显著减少对主机系统资源的需求,并且可以在设备内隔离维护键值对的开销。
背景与动机
- NVMe SSD资源需求:
基于块的NVMe SSD的资源使用情况进行测量,了解SSD达到饱和状态所需的最小资源(计算量),测试得出有文件系统吞吐量偏低,需要更多CPU饱和SSD。
(得到结果:一个CPU需要专门用于饱和一个NVMe设备,随着IO层次复杂需要更多CPU)
- 传统键值存储应用访问SSD三条路径存在问题:
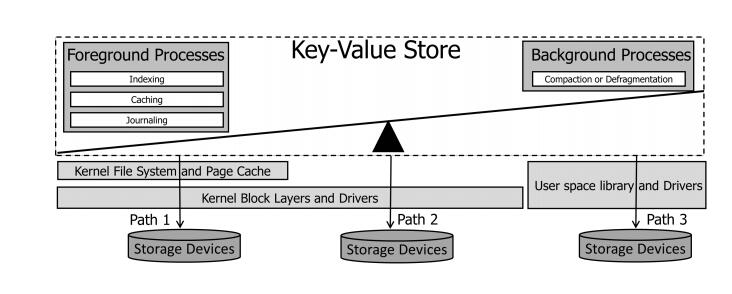 ①路径1:将用户数据存储在文件上,并使用内核文件系统、块缓存、块I/O层和内核驱动程序;
①路径1:将用户数据存储在文件上,并使用内核文件系统、块缓存、块I/O层和内核驱动程序;
比如RocksDB的压缩操作会影响性能。
②路径2:绕过内核文件系统和缓存层,但使用块层和内核驱动程序;
比如Aerospike,它利用本地、多线程、多核读写I/O模式。写被缓冲在内存中,一旦写满,写缓冲区就刷新到持久存储。与任何日志结构的写方案一样,随着时间的推移,磁盘块上的记录会因更新和删除而失效。碎片整理进程跟踪活动记录,并通过将活动记录复制到不同的块来回收空间。相关的读写放大会影响性能。
③路径3:使用用户空间库和驱动程序。
比如RocksDB-SPDK是支持SPDK的RocksDB,它使RocksDB能够使用用户空间SPDK驱动程序和相关的SPDK Blobstore文件系统(BlobFS)来存储其文件。BlobFS基于SPDK Blobstore,它拥有并将整个设备划分为1mb的区域,称为集群。Blobstore管理对blob的并行读写,blob由集群组成。Blobstore完全避免了页面缓存,其行为类似于DIRECT I/O。Blobstore还提供零复制、无锁、真正异步的读写存储设备。默认情况下,RocksDB-SPDK中WAL是被禁用的。由于WAL是RocksDB设计中不可或缺的一部分,如果没有日志,评估RocksDB- spdk将是不正确的。 - 挑战和瓶颈:
①多层干扰:在数据访问的漫长过程中,用户读写请求在提交给设备之前通常要经过多个I/O层,与请求处理相关的延迟也会增加。
②资源争用:键值存储需要在多个前台和后台进程之间进行平衡。为了利用设备带宽,随着前台进程数量的增加,后台进程的工作负载也会增加,从而导致系统变慢或停滞。这限制了节点的可伸缩性,因为更多的cpu专用于支持更少数量的高性能存储设备。
③数据一致性:预写日志WAL通常用于数据一致性。但是WAL将用户吞吐量减少了一半,此外WAL在前台生成同步写操作也使得降低设备利用率。
④读写放大:键值存储引入了垃圾收集、压缩和/或碎片整理等过程,这极大地增加了读写放大。 KV-SSD设计
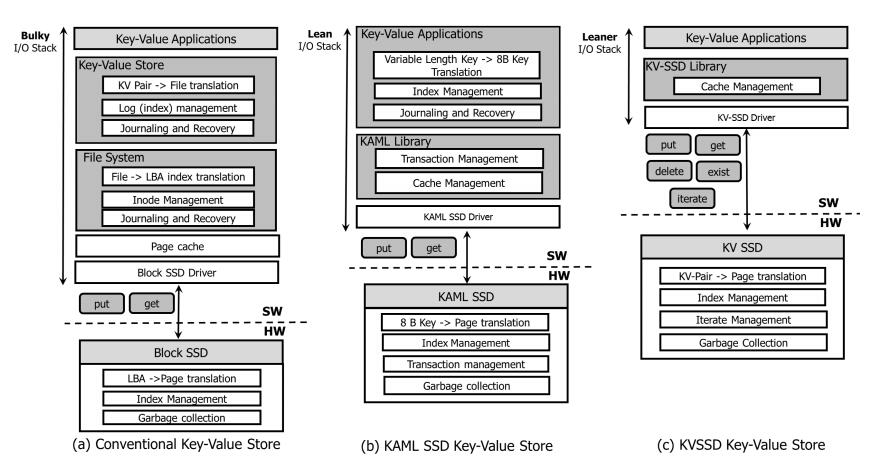
- 设计点如下:
①轻量级请求转换:
由于支持可变大小的键值对,因此不再需要键值到块的转换。应用程序可以直接创建请求并向KV-SSD发送请求,而无需通过任何遗留存储堆栈,从而减少了请求处理和内存开销。
②没有日志记录的一致性:
不需要在主机端维护键值对的元数据,从而消除了将元数据和数据存储在一起的日志记录或事务的需要。键值对的一致性现在在KV-SSD内部管理,使用其电池支持的内存请求缓冲区。保证每个键值请求在设备中要么具有全部一致性,要么没有一致性。因此,对于独立的键值对,主机端不需要预写日志(WAL)机制。
③读写放大减小:
KV-SSD的主机端读写放大系数保持为最优值1,因为它不需要为键值对存储额外的信息。在KV-SSD内部,因为可变大小的键在写入索引结构之前是散列的,所以它们仍然可以被认为是固定大小的键。因此,KV-SSD内部读写放大系数与块ssd中的随机块读写放大系数相同。
④内存占用小:
无论设备中有多少个键值对,KV-SSD占用的主机内存都是恒定的。它的内存消耗可以通过将I/O队列深度乘以键值对的大小和值缓冲区的大小来计算。且KV-SSD允许键值存储应用程序轻松采用无共享架构,因为设备之间不需要共享主数据结构,可以避免同步效应带来的可伸缩性限制。它可以避免共享数据结构上的锁争用,还可以消除查找与给定请求关联的元数据的按需读取。 键值存储管理
- 在现有的基于块的SSD固件中添加了对可变大小键和值的支持。
①命令处理:
设计了5个本机命令:put、get、delete、exist和iterate。put和get命令类似于块设备的write和read命令,附加了对可变大小的键和值的支持。delete命令用来删除键值对。exist命令用于使用单个I/O命令查询多个键的存在性。最后,iterate命令枚举与给定搜索前缀匹配的键,该前缀在KV-SSD中由4b位掩码表示。
例如,要处理一个put请求,首先从设备I/O队列中获取命令头并传递给请求处理程序。然后,启动设备驱动程序和设备之间的通信,以从主机系统传输键值对。一旦数据在设备DRAM中准备就绪,请求处理程序将请求传递给索引管理器。如图4所示,Index Manager首先将可变大小的键散列到设备内的固定长度键,并将其存储在本地哈希表中,然后将其合并到全局哈希表中进行物理偏移转换,最后Index Manager将键值对发送到flash通道。索引管理器还将键的前4b存放到称为迭代器桶的容器中,该容器用于对具有相同4b前缀的所有键进行分组。
除此之外,还支持可变大小键值(消除了为名称解析维护额外日志和索引的需求,从而简化了I/O堆栈)。
并且迭代器支持,键值应用程序通常需要组操作来维护对象。这包括再平衡、列表、恢复等。为了支持这些操作,KV-SSD提供了对迭代器的支持,迭代器可以列出、创建或删除一个组。在内部,所有匹配msb4b键的键都被容器化到迭代桶中,如图4所示。无论何时处理放置或删除操作,这些桶都以日志结构的方式更新,并定期由GC清理,如后面所述。
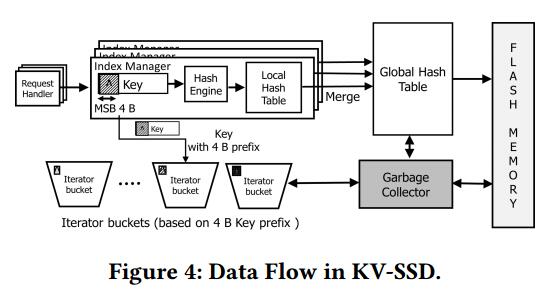 ②FTL和索引:
②FTL和索引:
扩展了基于块的FTL,支持可变大小的键值对。使用LBA作为键的传统基于页或基于块的映射技术不能作为KV-SSD的主要索引结构,因为键的范围是不固定的。使用多级哈希表作为KV-SSD的全局索引结构,用于快速点查询。全局哈希表被设计为包含设备中的所有键值对,并由所有索引管理器共享。每个索引管理器都有一个本地哈希表来临时存储更新,以减少主表上的锁争用。这个局部哈希表与bloom过滤器相关联,以减少读取时对索引结构的内存访问次数,以便快速检查成员关系。
③垃圾回收:
将SSD中的垃圾收集器更改为识别存储在flash页面中的键值对和迭代器桶中更新的键。在清理期间,GC扫描flash页面中的键,通过在全局索引结构中查找它们来检查它们的有效性,并丢弃已经删除的键-值对。 KV库和驱动
- KV-SSD库为用户应用程序提供编程接口。它包括一个原始键-值命令集的包装器和额外的特性,比如内存管理、键-值LRU缓存、同步和异步I/O、排序,以及一个模仿内存中KV-SSD行为的KV-SSD模拟器。默认情况下,KV库在内部使用非阻塞、异步I/O来提高性能。同步I/O是在异步I/O的基础上模拟的。通常,对异步I/O的支持是在内核的块I/O层中提供的,但是由于KV- ssd应用程序绕过内核I/O堆栈,我们将功能移到了KV驱动程序中。每当I/O完成时,KV驱动程序将I/O结果存储在内核内存中,并向事件文件描述符发送信号。然后,使用select()或epoll()等待I/O完成的用户将得到通知。
测试评估
- 测出键值存储需要的资源:确认为使用一个RocksDB- spdk实例,每个设备使用2个不带WAL的flush线程,每个设备使用8个带WAL的RocksDB实例。为了了解每个键值存储利用设备性能的潜力,我们测量了吞吐量、CPU和I/O利用率。
- ①最小化后台开销工作负载:
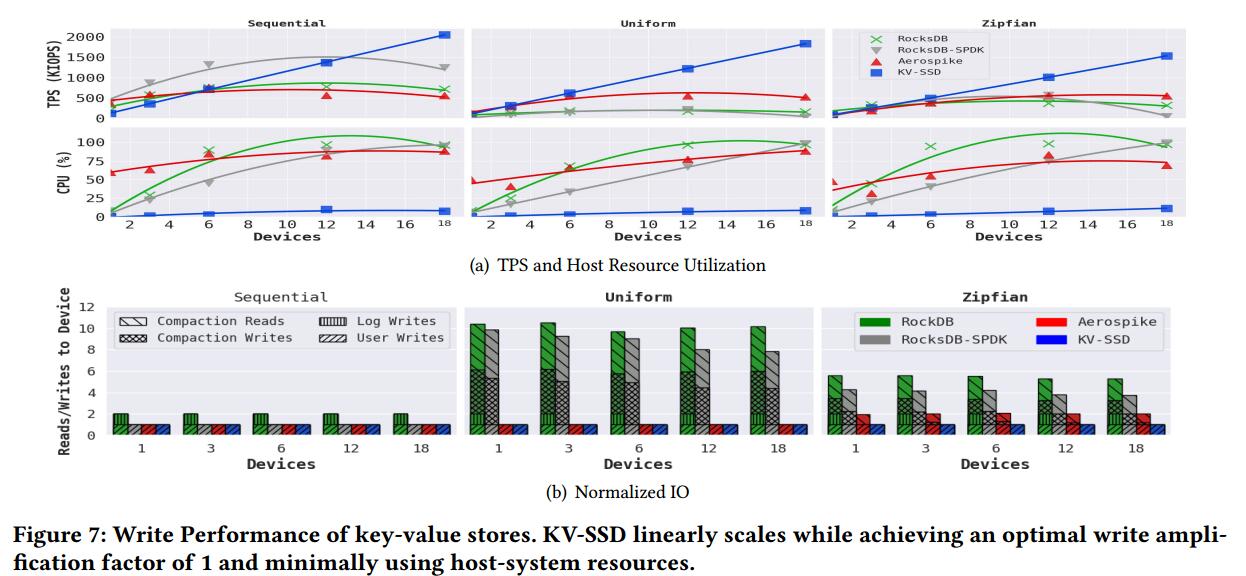
首先使用顺序工作负载来衡量每个键值存储的前台处理的可伸缩性,其中唯一的键是顺序生成和发送的,最大限度地减少了后处理的需要。结果显示在图5(a)的顺序工作负载列中。
当使用6个或更多设备时,RocksDB和Aerospike的性能受到CPU瓶颈的限制。6个设备中有48个RocksDB实例,每个实例包含一个活动I/O线程,即48个I/O线程在48个具有超线程的cpu上运行。之后其性能开始下降。Aerospike配置为每个设备有3个客户端和一个服务器,这显示了最佳的可扩展性能。它也会在CPU利用率达到80%后饱和。
由于RocksDB- spdk的异步特性和禁用了WAL,它比RocksDB和Aerospike显示出更好的设备和CPU利用率,但由于CPU瓶颈,它在12个设备后无法扩展。对于12个设备,由于每个RocksDBSPDK实例使用2个刷新线程,它占用了所有24个物理cpu,总共有24个异步刷新线程。
另一方面,KV-SSD随着设备数量的增加而线性扩展,所有18个设备只需要大约6个cpu。这种线性可伸缩性是通过将键值处理开销转移给设备来实现的,从而节省了主机系统中的CPU和内存资源。
图5(b)显示了运行基准测试时每个键值存储的主机端写放大。顺序工作负载列显示,总的I/O数量与用户对Aerospike、RocksDB-SPDK和KV-SSD所需的键值对数量相同。由于使用了WAL, RocksDB产生了更多的I/O。KV-SSD提供了与RocksDB相同的一致性级别,但没有日志记录,因为该基准中的键值对是独立的。图5(b)中另一个有趣的观察结果是,在所有工作负载中,KV-SSD的写放大明显更低,并且保持恒定。
- ②给后台添加工作负载:
在键-值存储的设计中假设键总是排序是不切实际的,因为键可以被散列、覆盖或删除。即使每个用户都有一个独立的键空间并提供排序的键,键值存储的性能仍然会受到影响,因为并行性降低了;每个请求都需要按顺序处理。因此,利用存储设备的内部并行性变得困难。为了探索这种重叠工作负载的影响,我们使用统一分布和Zipfian分布生成的键来测量性能,这两种分布可能分别包含10-20%和80%的重复键。
在统一工作负载的情况下,如图5(a)所示,我们发现RocksDB和RocksDB- spdk都受到压缩开销的影响,这需要大量的后台I/ o和内存,使前台进程停滞或变慢。由于这样的处理开销,RocksDB-SPDK的好处被抵消了。另一方面,Aerospike和KV-SSD保留了它们的性能特征。这是因为Aerospike不区分顺序键和均匀分布键,而KV-SSD在内部用自己的资源处理开销。我们还注意到,RocksDB- spdk的写放大比RocksDB低,因为默认情况下它比RocksDB更晚调用压缩。
在Zipfian分布中,背景开销的数量比均匀情况下要低。这是因为许多覆盖可以缓存在写缓冲区中,从而减少了写的数量,并且由于重复的键减少了压缩的数量。Aerospike的碎片整理过程也会随着这个工作负载启动,从而增加其写放大。
- ③YCSB工作负载:
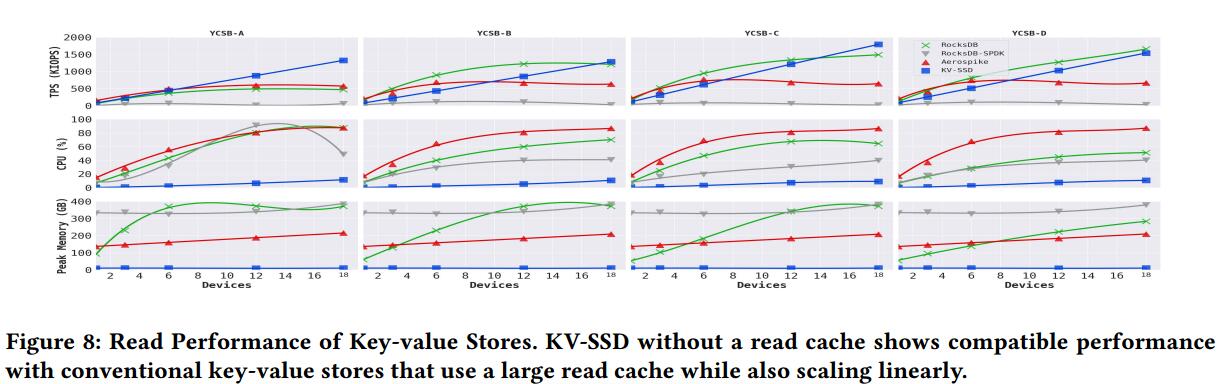 使用YCSB测量了每个键值存储的读和混合工作负载性能。YCSB-A和YCSB-B的读/写比例分别为50%和95%。YCSB-C包含100%的读操作,YCSB-D包含5%的插入操作和95%的读操作。除了YCSB-D之外,Zipfian分布用于键,YCSB-D使用最新分布,其中最近插入的记录位于分布的头部。
使用YCSB测量了每个键值存储的读和混合工作负载性能。YCSB-A和YCSB-B的读/写比例分别为50%和95%。YCSB-C包含100%的读操作,YCSB-D包含5%的插入操作和95%的读操作。除了YCSB-D之外,Zipfian分布用于键,YCSB-D使用最新分布,其中最近插入的记录位于分布的头部。
图6显示,没有缓存的KV-SSD可以线性扩展,同时提供与具有大型缓存的传统键值存储相当的性能,因为与其他系统不同,KV-SSD使用其内部资源。它的读处理不需要额外的I/O来查找元数据,因为设备内部有电池支持的DRAM。当有大量更新(YCSB-A)时,传统键值存储的整体性能受到其后台处理开销的影响。其他具有小覆盖的工作负载表现出与YCSB-C类似的性能特征,它只有读操作。由于工作负载分布不是zipfian就是最新的,所以大多数操作都是由内存观察到的。Aerospike使用自己的缓存,其性能在6个类似于其写性能的设备后仍然有限。- ④带缓存的KV-SSD:
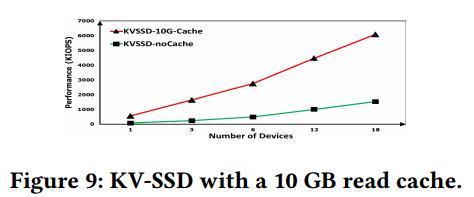 为每个KV-SSD实例添加10gb的LRU缓存并运行YCSB-C,每个KV-SSD实例的总体读性能提高了4到6倍,如图7所示,并且在内存利用率的一小部分上明显优于所有其他键值存储。为了在隔离其他性能影响因素(如其他插入或更新)的同时查看缓存效果,我们展示了来自YCSB-C(只读工作负载)的结果。在其他工作负载中也可以预期类似的改进。它的性能比RocksDB和其他系统至少高出4倍,并且消耗的内存也更少,最大内存消耗大约为180GB(18台设备,一半的RocksDB内存消耗)。
为每个KV-SSD实例添加10gb的LRU缓存并运行YCSB-C,每个KV-SSD实例的总体读性能提高了4到6倍,如图7所示,并且在内存利用率的一小部分上明显优于所有其他键值存储。为了在隔离其他性能影响因素(如其他插入或更新)的同时查看缓存效果,我们展示了来自YCSB-C(只读工作负载)的结果。在其他工作负载中也可以预期类似的改进。它的性能比RocksDB和其他系统至少高出4倍,并且消耗的内存也更少,最大内存消耗大约为180GB(18台设备,一半的RocksDB内存消耗)。结论
通过对生产中使用18块NVMe ssd的三个键值存储的性能分析,我们发现,高前台和后台处理的键值存储阻碍了快速存储设备的性能和可扩展性。因此,传统的键值存储要么表现出次优性能,要么限制了可伸缩性。为了减轻这种权衡,我们开发了KV-SSD,并探索了将其用作传统主机端键值存储的替代方案。我们表明,通过将数据管理移动到数据附近,可以简化庞大且冗余的遗留存储堆栈,并且可以显着减少主机资源消耗,同时在不影响数据一致性的情况下饱和设备带宽。通过实验评估,我们表明kv - ssd在显著降低内存和CPU消耗的情况下线性扩展,优于传统的主机端键值存储。



