发布日期:
2022-10-31
更新日期:
2023-06-14
文章字数:
4k
阅读时长:
14 分
文献阅读:
Asynchronous I/O Stack: A Low-latency Kernel I/O Stack for Ultra-Low Latency SSDs
摘要:
- 随着ssd发展,内核I/O堆栈内部的操作不再是可以忽略的部分,我们提出异步I/O堆栈(AIOS),本文提出如下措施:
- ①异步操作:使CPU的I/O操作与设备I/O重叠。
- ②轻量级块层:针对NVMe ssd,没有块I/O调度和合并,lbio取代bio和request。
一:介绍:
- 硬件不断发展,对于延迟极低的ssd,内核I/O堆栈在总I/O延迟中占了很大一部分并成为瓶颈,主流解决方法如下:
- ①用户进程直接访问存储设备:需要应用程序有自己的块管理层或文件系统。
- ②优化内核堆栈:例子包括:Ⅰ使用轮询机制来避免上下文切换的开销,Ⅱ在中断处理中删除下半部分,Ⅲ提出分散I/O命令,Ⅳ简单的块I/O调度等。
- 思想:当前的I/O堆栈实现需要许多操作来服务一个I/O请求:当应用程序发出读I/O请求时,将分配一个页并在页缓存中建立索引,然后,进行DMA映射,并分配和操作几个辅助数据结构(例如,Linux中的bio、request、iod),使用超低延迟ssd,执行这些操作所需的时间与实际的I/O数据传输时间相当。将这些操作与数据传输重叠可以大大减少端到端I/O延迟。
- 本文核心——Ⅰ:仔细分析read和fsync,确定了可以与设备I/O操作重叠的与I/O相关的CPU操作。
Ⅱ:为了进一步减少CPU开销,还引入了专门用于基于NVMe的ssd的轻量级块I/O层LBIO。(LBIO)。
- linux IO过程标准栈:
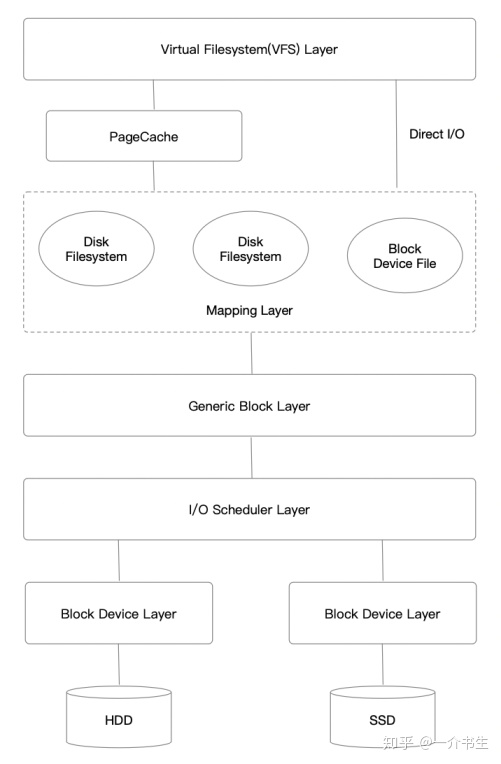
二:背景与动机:
- 2.1:存储设备比cpu慢得多,但超低时延ssd可以实现超低的I/O时延。而在内核中花费的时间量不会随着不同的ssd而改变,内核花费时间比例变大。在本文中针对Linux内核和Ext4文件系统中基于nvme的ssd的两个延迟敏感I/O路径(read()和write()+fsync())。
- 2.2:read路径:
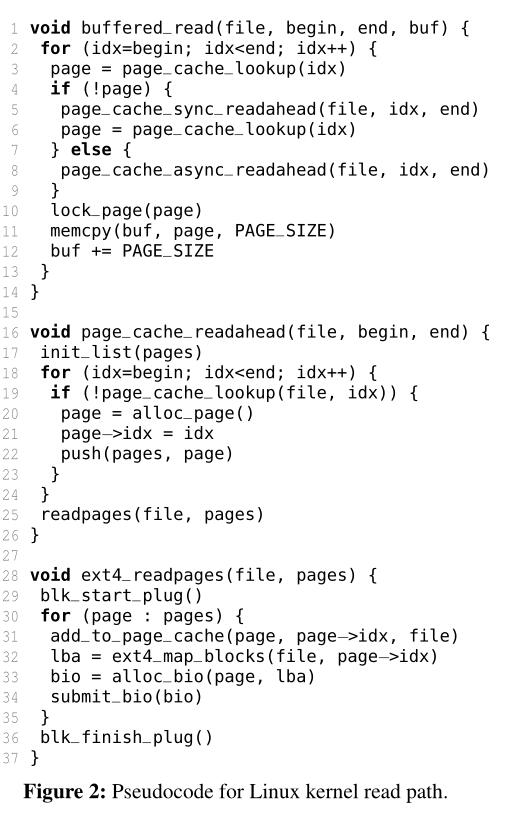
- VFS层:函数buffered_read(),它是页面缓存层的入口点。
- page cache层:当缓存丢失时(第3-4行)调用Page_cache_sync_readahead(),将缺失的文件块读入页缓存。它识别请求文件范围内所有丢失的索引(第18-19行),分配页面并将页面与丢失的索引关联起来(第20-21行)。最后请求文件系统读取缺少的页面(第25行)。
- file system层:在Ext4中ext4_readpages()将每个页面插入到页面缓存中(第30-31行),检索页面的逻辑块地址(第32行),并向底层块层发出块请求(第33-34行)。当调用blk_start_plug()时(第29行),块请求被收集到当前线程的插件列表中。Linux对线程发出的多个块请求进行批处理,以提高底层请求处理的效率(也称为队列插入)。当调用blk_finish_plug()(第36行)或当前线程进行上下文切换时,收集的请求将刷新到块I/O调度器。在向存储设备发出I/O请求后,线程返回其调用堆栈,并在函数lock_page()处阻塞(第10行)。当I/O请求完成时,中断处理程序释放页面的锁,这将唤醒阻塞的线程。最后,将缓存的数据复制到用户缓冲区(第11-12行)。
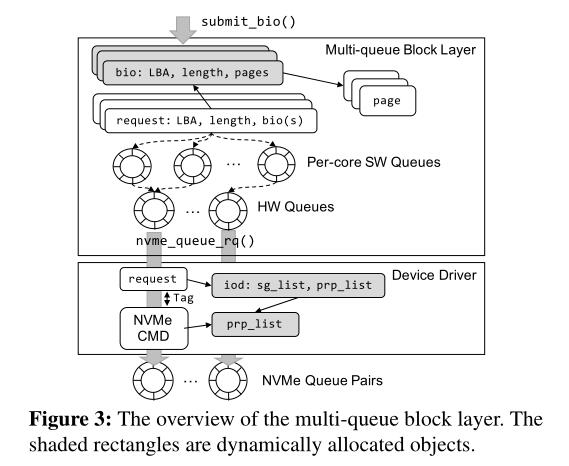
- blokc layer层:图3显示了多队列块层(这是Linux内核中NVMe ssd的默认块层)和设备驱动程序层的概述。在块层中,bio对象使用slab分配器进行分配,并初始化为包含单个块请求的信息(即,LBA、I/O大小和要复制的页面)(第33行)。
然后,submit_bio()(第34行)将bio对象转换为请求对象并将请求对象插入到请求队列中,在请求队列中执行I/O合并和调度。请求对象通过每个核心的软件队列(ctx)和硬件队列(hctx),最终到达设备驱动程序层。
- device driver层:使用nvme_queue_rq()将请求分发到设备驱动程序。它首先分配一个iod对象,这是一个具有分散/收集列表的结构,并使用它执行DMA(直接内存访问)映射,从而为已分派请求中的页面分配I/O虚拟地址(或DMA地址)。然后,分配一个包含NVMe协议中物理区域页(PRP)的prp_list,用分配的DMA地址填充。最后,使用发出给NVMe提交队列的request和prp_list创建一个NVMe命令。在I/O完成后,中断处理程序解除页面的DMA地址映射,并调用完成函数,该函数最终唤醒被阻塞的线程。
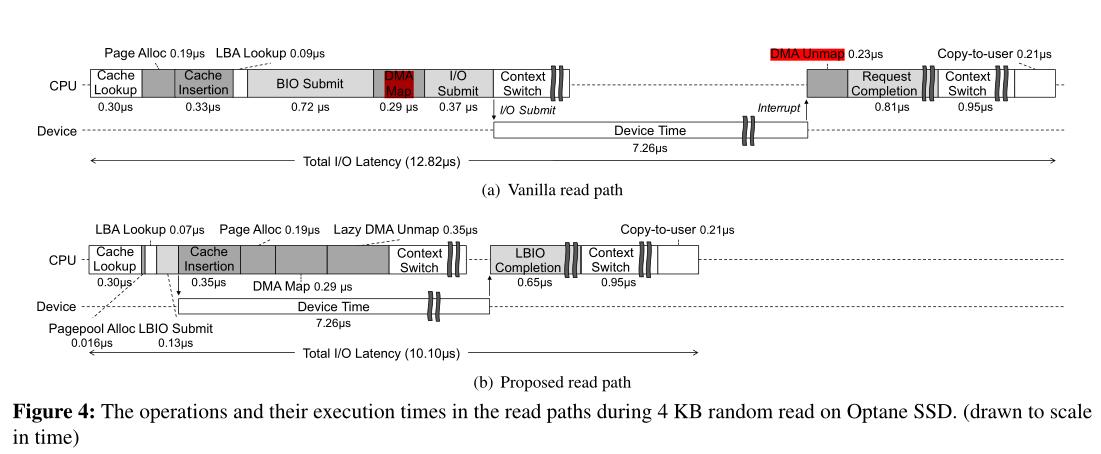
- !!!!!虽然上面描述了读路径中的基本操作,但写路径中的块层和设备驱动层的角色是相同的。
- 2.3:write路径:
- 当应用程序调用fsync()时,内核实际上执行写I/O,将脏数据同步到存储设备。而缓冲写路径没有机会与I/O重叠,因为它不执行任何I/O操作。另一方面,由于脏数据的回写以及文件系统中的崩溃一致性机制(例如,文件系统日志),fsync伴随着几个I/O操作。由于fsync在写路径上对应用程序性能影响最大,因此详细地研究它。
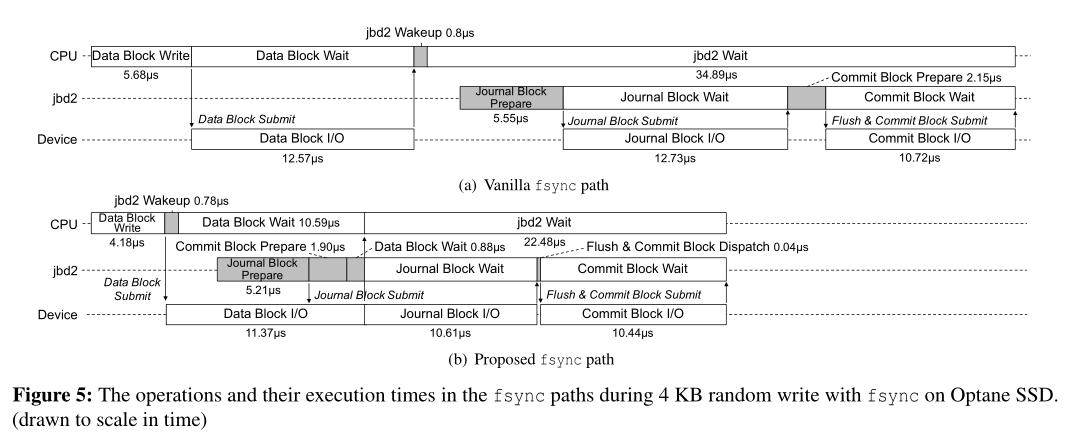
- 图5(a)显示了使用有序日志记录在Ext4文件系统上执行fsync调用时的操作及其执行时间。首先,应用程序线程为脏文件块发出写I/ o,并等待它们完成。然后,应用程序线程唤醒一个日志记录线程(Ext4中的jbd2)来提交文件系统事务。它首先准备将修改后的元数据(图中的日志块)写入日志区域,并发出写I/O。然后,它等待写操作完成。一旦完成,它就准备写提交块,并发出写I/O。在日志块写入和提交块写入之间强制执行一个flush命令,以强制执行写入的顺序。因此,对于一个fsync调用,总共会发生三个设备I/O操作。
- 在读取路径的情况下,也有机会将设备I/O操作与fsync路径中的计算部分重叠。如图5(a)所示,日志线程同步执行I/O准备和I/O等待。每个I/O准备包括在日志区域分配要写入的块,分配缓冲页,分配/提交bio对象,分配DMA地址,等等。如果这些CPU操作与之前的设备I/O时间重叠,那么fsync系统调用的总延迟可以大大降低,如图5(b)所示。
- 2.4:轻量级块层的灵感:
- Linux内核默认使用NVMe ssd的多队列块层,以很好地扩展多命令队列和多核cpu。该块层提供了块I/O提交/完成、请求合并/重排序、I/O调度和I/O命令标记等功能。
虽然块I/O提交/完成和I/O命令标记是必要的功能,但请求合并/重排序和I/O调度并不重要。多队列块层支持各种I/O调度器,但它的默认配置是noop,因为许多研究报告称,对于快速存储设备上的时延关键应用程序,I/O调度对于降低I/O时延无效。I/O调度也可以由设备端I/O调度功能代替。在超低延迟ssd中,请求合并/重排序的有效性也值得怀疑,因为它们具有较高的随机访问性能,而且找到相邻或相同的块请求的概率较低。
- 所以基于这些直觉,建议简化块层的角色,使其专门用于异步I/O堆栈,以最小化其I/O提交延迟。
三:AIOS:
- AIOS由两个组件组成:轻量级块I/O层(LBIO)和将I/O相关计算与设备I/O操作重叠的修改I/O堆栈。
- 3.1:轻量级块I/O层(LBIO):
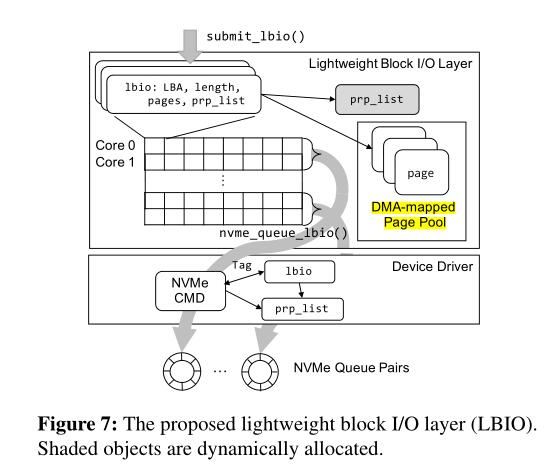
- ①LBIO专为低延迟NVMe ssd设计,只支持I/O提交/完成和I/O命令标记。图7显示了我们提议的LBIO的概述。
- ②与原始的多队列块层不同,LBIO使用单个内存对象lbio来表示单个块I/O请求,从而消除了原块层中bio到request的转换。每个lbio对象包含LBA、I/O长度、要复制的页面和页面的DMA地址。在lbio中包含DMA地址可以利用以下部分中解释的异步DMA映射特性。lbio只支持4kb对齐的DMA地址和多个扇区的I/O长度,以简化代码初始化和提交块I/O请求。假设使用页面缓存层,这种方法是可行的。与原始的块层类似,LBIO支持队列插入,以批量处理由单个线程发出的多个块I/O请求。
- ③LBIO有一个全局的LBIO二维数组,它的行专门用于每个核心,一组行被分配给每个NVMe队列对,如图7所示。例如,如果系统有8个核和4个NVMe队列对,则lbio数组的每一行与每个核一一对应,连续的两行对应一个NVMe队列对。当NVMe队列对的数量等于内核的数量时,就可以像现有的多队列块层一样,实现无锁lbio对象分配和NVMe命令提交。lbio对象在全局数组中的索引被用作NVMe命令中的标记。这消除了原始块层中耗时的标记分配。
一旦提交了一个lbio,线程直接调用nvme_queue_lbio()来调度一个NVMe I/O命令。
注意,LBIO不执行I/O合并或I/O调度,因此可以显著降低I/O提交延迟。在没有I/O合并的情况下,两个或多个lbio可以访问同一个逻辑块。这可能发生在读路径中,并由页面缓存层解决(参见第3.2节)。但是,这不会发生在写路径中,因为页缓存会同步脏页的回写。
- 3.2:read路径:
- 预加载段树:
对于读操作,检索与丢失的文件块对应的LBAs是发出块请求的必要步骤,因此该操作应该位于关键路径中。我们的建议不是将这一步从关键路径上移开,而是将重点放在减少延迟本身。Linux Ext4文件系统的实现将逻辑到物理文件块映射缓存到内存中,这个缓存称为区段状态树。当可以在缓存中找到映射时,获取LBA所需的时间相对较短;然而,当没有找到映射时,系统必须发出一个I/O请求来读取丢失的映射块,从而导致更长的延迟。
为了避免这种不必要的开销,我们采用了平面分离方法。在控制平面(例如,打开文件),整个映射信息被预加载到内存中。通过这样做,数据平面(例如,读和写)可以避免映射缓存丢失造成的延迟延迟。缓存整个树的内存成本可能很高;在我们的评估中,最坏情况下的开销是文件大小的0.03%。然而,当空闲内存很少时,区段缓存会清除不太可能使用的树节点,以保护空闲内存。为了进一步减少空间开销,可以选择性地将该技术应用于需要低延迟访问的文件。
- 异步页面分配/DMA映射:
为每个页面分配一个DMA地址(DMA映射)需要大量的CPU周期,所以我们为每个核心维护了一小组dma映射的空闲页面(一个4 KB dma映射页面的链表)。使用这种结构,只需要少量内存指令就可以从池中获取空闲页面。在发生设备I/O操作时,通过调用页面分配和DMA映射来重新填充所消耗的页面。
- 延迟页缓存索引:
在普通内核中,页面缓存充当同步点,它决定是否可以发出文件的块I/O请求。允许将其缓存页成功插入到页面缓存中的文件块发出块请求(图2中的第31行),并且使用自旋锁来保护页面缓存不受并发更新的影响。
因此,同一个文件块不会发生重复的I/O提交。但是,如果在向设备提交I/O命令后将页面缓存插入操作延迟到一定程度,则有可能导致另一个线程错过同一文件块,从而发出重复的块请求。确切地说,如果另一个线程在I/O请求提交之后但在页面缓存条目更新之前访问页面缓存,就会发生这种情况。
我们的解决方案是允许重复的块请求,但在请求完成阶段解决它们。尽管有多个块请求与同一个文件块相关联,但页缓存中只有一个页被索引。然后,我们的方案将其他页面标记为已废弃。如果被标记为废弃,中断处理程序将释放与已完成的块请求相关的页面。
- 延迟DMA解映射:
读路径中的最后一个长延迟操作是DMA解除映射,它发生在设备I/O请求完成之后。普通读路径在中断处理程序中处理这个问题,中断处理程序也在关键路径中。我们的方案将此操作延迟到系统空闲或等待另一个I/O请求时(图4(b)中的Lazy DMA unmap)。
- 3.3:write和fsync路径:
①具体来说,我们将日志线程中的计算部分与相同写路径中的前面I/O操作重叠。如图5(a)所示,有两种I/O准备操作:日志块准备和提交块准备。每个准备操作包括分配缓冲页,在日志区域分配块,计算校验和和块和设备驱动层内的计算操作。因为这些操作只修改内存中的数据结构,所以它们不依赖于同一写路径上的前一个I/O操作。
②我们更改fsync路径,如图5(b)所示。在调用fsync系统时,应用程序线程首先发出脏数据页的回写。然后,它提前唤醒日志线程,使数据块I/ o与日志线程中的计算部分重叠。应用程序线程最后等待回写I/ o的完成以及日志提交的完成。当数据块I/O操作发生时,日志线程准备日志块写并发出它们的写I/O。然后,它准备提交块写,并等待完成与当前事务相关的所有前面的I/O操作。一旦完成,它发送一个flush命令到存储设备,以使之前的所有I/O持久,最后使用一个透写I/O命令(例如,SATA中的FUA)发出提交块的写I/O。
- 3.4:实现:
四:评估:
- read性能:①随机读取延迟。②轮询在延迟方面优于中断(消除了上下文切换)。③随机读取的吞吐量。④顺序读取带宽。
- write性能:①fsync性能。②fdatasync性能。
- 性能分析:读,写,安全成本。
- 现实应用:①键值存储。②存储基准和OLTP工作负载。



